微软推出MMLU-CF基准测试 确保大语言模型评估无污染
时间:2025-07-18 18:55
小编:星品数码网
在人工智能领域,大语言模型(LLM)的迅猛发展为各行各业提供了新的可能性。如何有效评估这些模型的能力,确保评估结果的准确性和公正性,成为研究者们迫切需要解决的问题。微软亚洲研究院推出了一项新基准测试——MMLU-CF(Massive Multitask Language Understanding-Cleaned Framework),旨在消除数据污染对评估结果的影响,从而为大语言模型的性能评估提供更加可靠的工具。
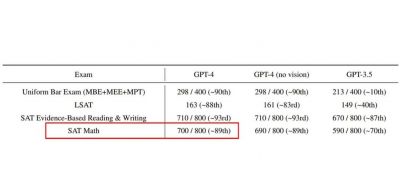
MMLU与数据污染问题
MMLU基准测试在业界得到广泛应用,帮助研究人员对大语言模型进行多任务能力的评估。由于开放源代码和多样化的训练数据,现有的基准测试不可避免地存在数据污染问题。这种情况可能会导致评估结果的失真,进而影响研究人员对模型能力的正确理解。因此,开发一个无污染的评估基准成为了亟需解决的任务。
MMLU-CF的诞生
为了解决上述问题,微软推出的MMLU-CF基准测试整合了严格的去污染策略和更广泛的数据收集来源。MMLU-CF的数据集设定了20,000道多项选择题,分为10,000道验证集题目和10,000道测试集题目。验证集题目为开放源代码,以促进透明度,而测试集则保持闭源,避免潜在的数据泄露,以确保评估结果的公正性。
MMLU-CF基准覆盖14个学科领域,包括健康、数学、物理、商业、化学、哲学、法律、工程等,为大语言模型提供了全面而深刻的评估标准。这一新兴基准测试的推出,标志着对大语言模型性能评估的一次重要革新。
去污染策略
MMLU-CF基于三条去污染规则设计数据集,这三条规则旨在减少模型对训练数据的依赖,并且增加推理的难度。具体而言:
1. 改写问题:通过对问题进行重构,有效降低模型记忆已见数据的可能性。
2. 打乱选项:改变题目选项的顺序,避免模型通过记忆选项的位置答对问题。
3. 随机替换选项:在选项中引入随机替换,增加模型的推理挑战。
通过这些有针对性的设计,MMLU-CF确保了评估的公正性和无污染性。
评估结果与模型表现
基于MMLU-CF的评估结果显示,包括OpenAI的最新模型o1、Deepseek-R1和Deepseek-V3在内的一些主流语言模型的性能表现显著不同。这些模型在MMLU-CF测试集上的得分,通常都低于它们在传统MMLU基准测试中的得分。例如,OpenAI o1在MMLU-CF测试集上获得85.5%的得分,相较于在传统MMLU上的92.3%得分,下降幅度明显。这一现象突显了MMLU-CF基准测试在挑战性和严谨性上的优势。
值得注意的是,MMLU-CF的发布不仅改变了模型的性能排名,还揭示了不同规模模型在去污染测试中的表现差异。通常规模较小的模型在这样的基准测试中表现得更为脆弱,容易受到数据污染的影响。通过MMLU-CF的评估,研究者能够更加深入地理解模型的泛化能力,进而对其进行优化。
研究意义与未来展望
MMLU-CF的推出,将为大语言模型的研究提供一个标准化、透明且公平的评估框架。通过去污染的评估,研究者不仅得以更准确地把握模型的有效性,还可以为未来的研究和模型改进提供宝贵的参考数据。
随着MMLU-CF的传播与应用,期待它能激励更多的研究者关注评估标准的公正性与可靠性。在不断进步的人工智能领域,实现真正的技术突破需要在各环节中严格把控数据质量。通过MMLU-CF基准测试,微软不仅推动了大语言模型评估方法的革新,也为整个人工智能研究的进一步发展奠定了坚实基础。
MMLU-CF以其独特的去污染策略和更为全面的数据集,为大语言模型的评估提供了一种可持续的解决方案。在未来,我们期待看到越来越多的研究者在这个新基准下进行探索,为大语言模型的演进开创出新思路。
