研究揭示AI在认知测试中表现欠佳,凸显人类独特能力珍贵性
时间:2025-02-18 07:50
小编:小世评选
在人工智能快速发展的今天,很多人开始质疑人类的独特性和不可替代性。一项新近来自以色列的研究让这一思考变得更加深刻。该研究发现,大部分主流的AI语言模型在认知能力测试中表现得相当不理想,甚至可以说是尴尬,仅有OpenAI的ChatGPT4o稍微过关。这使人们不禁思考,这是否揭示了人工智能的局限性,同时也凸显出人类能力的珍贵之处。
人类独特能力的珍贵性
随着智能技术的不断进步,人类在许多领域的角色开始发生变化。AI虽然在数据处理和生成文本方面表现优异,但其在认知能力上的不足却让我们重新审视自身的价值。以色列哈达萨医学中心进行的研究揭示了这样的现实:尽管AI技术在许多任务上已经显示出强大的潜力,但在需要“理解”与“推理”的认知任务中,它们却显得无能为力。
在研究中,科学家评估了四个主流大语言模型的认知表现,分别是OpenAI的ChatGPT4、ChatGPT4o、Google的Gemini 1.0和1.5、以及Anthropic的Claude 3.5 Sonnet。虽然这些模型在自然语言处理和各种数据分析上展现出色,但在真正的“思考”上,它们依然与人类有着显著的差距。
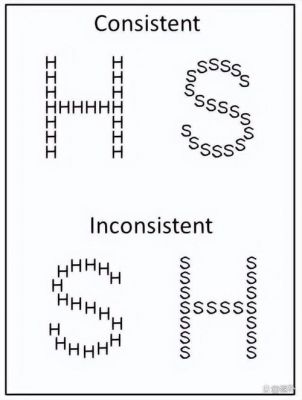
AI模型的认知能力测试
为了评估AI的认知能力,研究者们使用了斯特鲁普测试,这是一个经常用于检测人类认知能力的经典测试。在该测试中,参与者需要读取一个词的颜色,而该词可能是用不同颜色书写的,比如“红”这个词可能以蓝色展示。结果显示,只有ChatGPT4o能够相对顺利地完成此任务,其他模型则表现得十分混乱。
这一现象背后的含义并不仅仅是AI的表现不佳,更是人类思维方式的差异。AI在处理复杂的认知任务时明显显示出能力不足。例如,在Navon图形测试中,参与者需要从一个由小字母组成的大字母中识别出大字母,而AI模型却反其道而行之,先识别小字母,再试图组合成大字母,这样的反应速度和效率远不如人类。这一结果在视觉空间能力和执行功能任务的测试中表现得尤为明显。
另一个显著的例子是在AI模型执行线路连接的任务中。人类能够快速而准确地完成从一个点连接到另一个点的任务,但AI在这个过程中不仅无法完成,还经常出现记忆失效的情况。这些崩溃的例子进一步说明,当前的AI在应对多元复杂任务时仍显得吃力不讨好。
AI技术的应用局限
由此针对AI技术的期待不应被夸大。虽然AI在各行各业应用广泛,但其在情感理解和人际沟通方面的局限则让我们不得不重新审视它的应用场景。在医疗、法律、艺术等行业,真正的成功往往需要深厚的同理心和情感共鸣。人类医生能够凭借过去的经验、直觉,感知病人的情感变化,这种能力是目前的AI所无法模拟的。即便AI可以通过分析数据判断出病人的身体状况,但其对情感的理解却显得无能为力。AI的局限性不仅降低了其在复杂社会行为中的适用性,更明确了人类在这一领域的不可替代性。
这项研究不仅揭示了AI在认知测试中的表现不尽如人意,更加深了我们对人类独特能力的认识与珍视。在智能技术飞速发展的今天,尽管我们欣赏AI的许多优点,但不能忽视的是,情感、同理心以及经验判断的能力是人类的独特之处。人类的智慧和情感是无法通过简单的数字和算法进行替代的。利用AI作为辅助工具,提高我们的工作效率,而非将其视为全能的替代者,将是我们未来应对智能时代的一种理性选择。希望这项研究能引发更多关于人机关系的思考,大家也可以在评论区分享你们的观点。
