DeepSeek-V3技术报告发布:671B参数的混合专家语言模型引领AI性能新标杆
时间:2025-02-07 04:10
小编:小世评选
在人工智能领域,性能的提升一直是研究者们不懈追求的目标。近日,DeepSeek团队发布了《DeepSeek-V3技术报告》,揭示了一款具有革命性意义的混合专家(Mixture of Experts, MoE)语言模型——DeepSeek-V3。这款模型具备671B的庞大参数量,并通过创新的架构与训练策略,成功地在保证高性能的同时降低了经济成本,为 AI 发展树立了新的标杆。
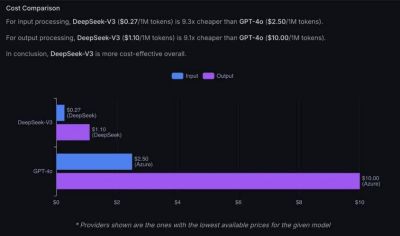
模型架构与创新
DeepSeek-V3采用了多头潜在注意力(Multi-Head Latent Attention, MLA)和专有的DeepSeek MoE架构。通过这些创新的设计,该模型能够在每个令牌的处理过程中激活高达37B的参数,展现出卓越的性能和灵活性。这种架构的优势在于,能够在多个任务上实现动态的资源分配,提升计算效率与响应速度。
值得一提的是,DeepSeek-V3还引入了辅助无损负载均衡策略和多令牌预测训练目标,这些新策略有效提升了模型的训练效果与推理性能。负载均衡的设计确保了在高并发的情况下,各个专家模块能够均匀分配计算任务,从而避免资源的浪费。
训练过程与优化
在训练阶段,DeepSeek-V3支持 FP8 混合精度训练,利用DualPipe算法优化训练框架,克服了跨节点 MoE 训练的通信瓶颈。这一系列技术改进实现了接近全计算与通信的重叠,使得模型训练过程更加高效。
据报告显示,DeepSeek-V3仅用2664K H800 GPU小时即可完成预训练任务,整体训练成本为2788K H800 GPU小时(约557.6万美元)。在预训练阶段,模型在14.8T的高质量多样化令牌上进行训练,确保了数据的多样性和高效性,同时训练过程也因其稳定性而获得高度评价。
性能评估与应用
通过一系列基准测试与评估,DeepSeek-V3-Base在多个标准测试中表现突出,毫问地成为了现阶段最强的开源基础模型之一。尤其是在代码理解及数学任务方面,DeepSeek-V3展现出明显的优势,其聊天版本的性能更是可以与现有领先的闭源模型一较高下。这一表现预示着DeepSeek-V3在实际应用中的广泛潜力,能够为开发者和企业提供强大的技术支持。
后训练阶段与微调
在完成预训练后,DeepSeek团队还进行了监督微调(Supervised Fine-Tuning, SFT)和强化学习(Reinforcement Learning, RL)的后训练阶段。这一过程使得模型的实际应用更贴近人类的偏好,从而进一步提升了模型的整体性能。通过这种方式,DeepSeek-V3不仅能够在技术层面上一展才华,更能在实际使用中提供更加优质的体验。
硬件设计与未来展望
在报告的部分,DeepSeek团队还针对未来的硬件设计提供了改进建议,包括对通信硬件和计算硬件的期望。随着模型规模的不断扩大,传统硬件架构可能面临着挑战,因此新硬件的发展将直接影响到大规模模型的训练效率和效果。
整体而言,《DeepSeek-V3技术报告》提供了一份详尽且具前瞻性的分析,明确指出了当下AI领域中混合专家模型的核心优势和未来发展方向。DeepSeek-V3以其671B的参数规模、创新的架构设计、优越的训练效果以及出色的实际性能,毫问地为我们展示了AI发展的新标杆。未来,随着技术的不断进步与硬件的逐步改善,DeepSeek-V3有望在更多领域中发挥其潜力,推动人工智能行业的进一步发展。
