上海AI Lab通过强化学习超越DeepSeek,取得数学推理新突破
时间:2025-02-22 04:50
小编:星品数码网
近年来,人工智能(AI)领域迅速发展,尤其是在自然语言处理(NLP)和数学推理等应用上。上海AI实验室近日宣布,该实验室基于强化学习的最新研究成果,不仅成功超越了DeepSeek模型,还在数学推理任务上取得了显著的突破。此次研究不仅为AI的数学推理能力提供了新视角,也在强化学习领域开辟了新的方法。
研究团队通过微调Qwen2.5-32B-Base模型,引入了一种基于结果奖励的强化学习新范式。在此过程中,研究者发现了当前大模型在数学推理任务中存在的“三重门”困局。具体而言,是二元反馈机制使得模型在面对复杂推理时优化变得困难;在长思维链中局部的正确步骤可能误导模型;,传统的蒸馏方法导致了参数规模的军备竞赛的局面。
为了应对这些挑战,研究团队重新审视了强化学习在数学推理中的应用,并在理论推导与实践实验中进行了深入研究。经过多次严格的试验,他们提出了一种新的结果奖励强化学习算法,并出了三项重要
1. 在二元反馈环境下,通过最佳轨迹采样(BoN)的行为克隆,可以有效学习最优策略;
2. 必须通过奖励重塑来保持策略优化目标的一致性;
3. 不同序列部分对最终结果的贡献是不同的,因此需要更加细化的奖励分配函数,而这一函数可以通过结果奖励的学习来获得。
通俗地说,实验室的研究表明,借助强化学习而无需依赖超大规模的模型(如DeepSeek-R1的蒸馏方法),就能实现令人瞩目的效果。
在对强化学习训练的不同策略进行比较和分析后,研究团队决定将训练期间所用的数据、起点以及最终生成的模型全部开源,以促进社区的公平比较和进一步研究。这一举措不仅体现了团队的开放精神,也为未来的AI研究打下了基础。
针对数学推理任务中的困难,研究团队提出了一种新的策略优化框架,通过理论创新推动算法改进,并证明了其有效性。在样本采样的过程中,研究团队发现,在二元反馈机制下,包含正确答案的最佳采样策略,会使得模型训练更加有效。因此,他们在正样本的训练中引入模仿学习,同时避免直接惩罚负样本,这种方法有助于维护梯度更新的一致性。
针对复杂的长推理链问题,研究团队设计了一种token重要性估计器。通过构建累积形态的奖励函数,团队能够将结果奖励逆向溯源到每一步推理。这种反向分解方式显著提高了模型在长序列任务中的表现。
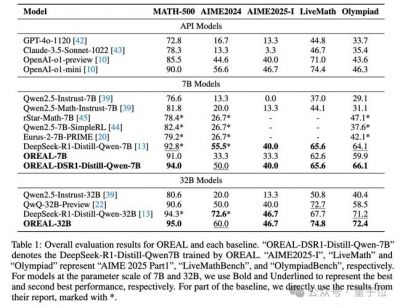
实验结果显示,在7B和32B规模的模型上,研究团队仅利用4千条高质量训练样本进行实验。在7B模型上,Oreal-7B在MATH-500数据集上达到了91.0的pass@1准确率,这是首次通过纯强化学习方法而非蒸馏实现如此高的精度。这一突破为基于强化学习的模型提供了新的里程碑,并超越了包括OpenAI-O1-Mini等更多参数量的模型。
在32B规模的模型上,Oreal-32B也在MATH-500上达到了95.0的成绩,不仅超越了同级别的DeepSeek-r1-Distill-Qwen-32B,更是为32B模型设定了新的状态-of-the-art(SOTA)记录。
除了模型改善外,研究团队还注意到不同基座模型在强化学习后的性能上限各有不同,其中,模型的基础性能越强,经过强化学习训练后表现提升越明显。研究团队也观察到,部分情况下模型性能没有得到提升乃至下降。这可能与训练语料的质量、难度和数量等因素密切相关,为未来的研究提供了更加广阔的探索空间。
在部分,虽然DeepSeek-R1的成功引发了社区对大语言模型的关注,研究团队也提出,算法和模型性能的比较往往受到不同训练方针的影响。因此,他们决定将整个强化学习过程中的训练数据、模型以及训练代码全面开源,这为AI领域的共同发展提供了有力支持。
上海AI实验室的这项研究展示了强化学习在数学推理领域应用的巨大潜力,同时也为未来的AI研究指出了新的方向。随着更多高质量数据集的提供以及不断深入的算法探索,AI在数学推理和其他复杂任务中的能力有望得到进一步增强。对于希望参与这一领域深入研究的学者和实践者而言,上海AI实验室的项目链接和开放资源是不可或缺的宝贵财富。
