华为打破技术壁垒,成功训练万亿参数大模型,告别NVIDIA时代
时间:2025-05-31 13:15
小编:星品数码网
随着人工智能技术的不断深入发展,万亿参数大模型的训练已经成为行业的最高追求之一。在这一领域,华为成功实现了超大规模的MoE(Mixture of Experts)模型训练,打破了以往的技术壁垒,不仅展现出强大的计算能力,也标志着中国在这一领域的自主创新迈入了新阶段,告别了长期依赖NVIDIA的局面。
技术挑战的背后
开展万亿参数大模型的训练并不是一件轻松的事,技术团队面临着四大障碍:优化参数配置、高效的路由机制、巨大的通信开销及整体训练效率的提升。在过去,科研人员多次尝试,但由于技术资源的限制,这一目标一直未能实现。华为通过一系列针对性的技术创新,成功克服了这些关键难题。
华为的创新举措
华为的技术团队在针对这些问题的解决方案中采取了全方位的优化策略。在MoE结构的选型以及昇腾NPU的亲和结构优化上,团队进行了细粒度专家与共享专家的组合实验,确保模型计算资源的高效利用。在计算与存储的亲和性优化上,通过增大模型的隐藏层大小同时减少激活参数,有效提升了模型的运算能力,进而提高了训练时算力的利用率。
在并行计算方面,团队采取了TP-extend-EP的策略,将TP组与EP组合成立32组,确保计算效率不因参数拆分而降低。通过减少计算和负载资源的闲置,整个模型的算力利用率(MFU)达到了30.0%,相比之前提升了58.7%。
联系专家负载均衡
在训练MoE模型中,负载不均衡问题是纾解模型性能的关键痛点。华为的研究团队针对这一问题研发了一种全新的EP组负载均衡损失算法,通过分配任务使得专家之间的工作负载更加均衡。此举不仅避免了因资源分配不均而可能导致的效率下降,还能够在数据传输中节省显著的成本。
例如,在一项关于200亿参数(20B)的先导MoE模型上进行的实验中,团队使用了“drop-less”方案以应对专家负载的不均衡现象,验证了该方案在训练效率上的显著优势。
篇章结构的重点优化
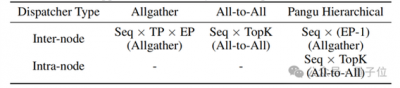
除了负载均衡,华为还在系统优化的路径上进行了深入探索。采用分级EP通信机制,团队有效减少了跨机通信量,通过在每个设备中优先进行token的排序与处理,极大地提升了数据的交换效率。自适应前反向掩盖策略(Adaptive Pipe Overlap Mechanism)的引入,则进一步减小了EP通信耗时间的比重,提高了整体计算效率。
数据集的严格构建
在数据集构建方面,团队始终坚持严格的数据质量控制,重点加强语料库的多样性和复杂性。通过对长链思维样本的结构化设计,确保了模型在推理轨迹上的准确性。在后训练阶段引入指令微调策略,以增强模型在广泛领域内的应用性能。
突破性的技术应用
这些技术创新与优化不仅使得华为在训练万亿参数大模型上实现了质的飞跃,更在不同任务中展现出了优异的性能。例如,在数学推理与代码生成等高难度测试中,华为的盘古Ultra MoE模型表现出色,展现出了卓越的推理与解决问题的能力。
展望未来
展望未来,华为的这一成功不仅是技术层面的突破,更是中国在全球人工智能领域战略地位的提升。随着技术的不断迭代与应用场景的扩展,盘古Ultra MoE将为多个行业的智能化转型提供强劲动力,并助力中国在新一轮科技革命中占据制高点,为全球科技进步贡献更多的“中国智慧”。
在这场技术战役中,华为向全球展示了其卓越的研发能力和创新精神,为万亿参数模型的未来走出了坚定的一步。正如华为所期望的那样,未来的智能时代将因其而变得更加光明。
