xAI推出Grok 3,算力堆积再现AI模型突破
时间:2025-02-21 16:40
小编:星品数码网
2023年2月18日,埃隆·马斯克旗下的人工智能公司xAI推出了最新的大型语言模型——Grok 3。这一重磅消息不禁让业内人士再次关注起算力堆积的意义。尽管Grok项目起步较晚,但其在MMLU(大规模多任务语言理解基准测试)上的表现已经与ChatGPT平起平坐,Grok 3与其轻量化版本Grok 3 mini在多个关键性能指标上也展现出超越Gemini、DeepSeek和GPT-4o等竞争对手的强劲能力。
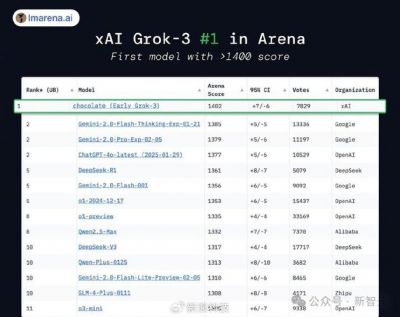
Grok 3的训练是在xAI位于孟菲斯的Colossus超算中心完成的。根据xAI的披露,该超算中心的算力已经实现了翻倍,当前拥有的英伟达GPU总量达到20万颗。这一硬件的强大,使得Grok 3在性能上可圈可点,给业界带来了惊喜。在不少人看来,Grok 3的成功尤为印证了“靠算力堆积的‘大力出奇迹’”这一理论在当今AI领域依然适用。
值得注意的是,AI领域的诸多专家和研究者对于Grok 3的表现给予了高度评价。作为前OpenAI的研究员以及前特斯拉AI负责人,Andrej Karpathy在成为Grok 3的早期用户后,他在社交媒体上发布了对Grok 3的测评,指出其逻辑推理能力明显出色,甚至与OpenAI的o1-pro模型相提并论。需要指出的是,后者的每月使用费用高达200美元,而Grok 3在性价比上的优势显露。同时,他也坦承了Grok 3在某些功能上的不足,例如搜索功能DeepSearch偶尔会出现虚假信息以及事实错误。
Karpathy对此表示,“考虑到该团队大约1年前才从零开始,能够在如此短的时间内,取得接近行业顶尖水平,真是令人难以置信。”他强调了Grok 3表现背后的创新与努力。
从行业角度来看,Grok 3的成功不仅是技术上的突破,更是对算力投入合理与否的深刻反思。科技领域的分析人士普遍认为,Grok 3的成功是得益于算力的大规模堆积。Maginative的创始人Chris McKay认为,xAI的迅速崛起与其在创新计算基础设施与大量计算资源的获取上分不开。他还提到,随着xAI计划进一步发展更多超算集群,公司未来的模型能力提升将指日可待。
对于Grok 3的开发,沃顿商学院的人工智能教授Ethan Mollick亦表示,Grok 3完全符合其预期,人工智能的发展速度与算力依然是保持竞争优势的护城河。他提到,“人才和芯片是打造前沿模型的公开秘诀。”他进一步说明,虽然护城河并不宽广,但却足以淹没许多初创企业。
对于xAI而言,Grok 3的成功同样标志着巨额投资的回报。Shelly Palmer,雪城大学公共传播学院教授及咨询公司首席执行官,指出,Grok 3的护城河已被资金渗透。当前英伟达H100 GPU的价格在3万至4万美元之间,即使马斯克获得了折扣,这一投资依然可能高达30亿至50亿美元。根据公开信息,OpenAI在训练GPT-4时耗费了约2.5万张A100 GPU,而H100的训练能力更是远超A100,这进一步说明了算力在大型模型开发中的核心价值。
在面对DeepSeek等新兴竞争者的冲击时,行业也引发了针对“缩放法则”的探讨。传统的缩放法则是基于增加模型规模、数据量和算力来提升模型表现,但效益递减的问题可能正在显现。科技博主Zain Kahn指出,尽管近期有观点认为向大模型投入更多资源将不再有效,但Grok 3的表现向我们证明了这一担忧是多余的。xAI仅在两年内便迅速与顶尖公司展开激烈竞争,证明其实力。
时,华泰证券在其研报中也强调了算力在模型预训练过程中的重要性,指出尽管预训练数据目前存在瓶颈,但是合成数据、强化学习数据等工程能力优化有望逐步破解这些瓶颈。Grok 3是算力堆积仍能带来突破的有力证明。
整体而言,Grok 3的发布不仅是xAI的一次重大成就,也是对AI领域算力聚合重要性的有力践行。随着行业技术与战略的不断演变,未来的AI发展势必将在算力与创新的交汇中展现出更广阔的前景。
