DeepSeek-R1引发硅谷恐慌,AI行业格局或将重塑
时间:2025-01-28 08:40
小编:小世评选
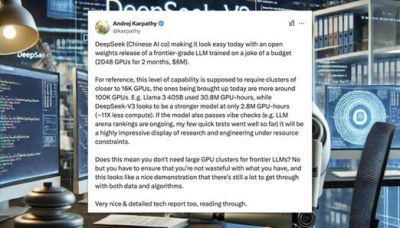
在全球人工智能(AI)技术不断进步的大背景下,来自中国的AI创业公司DeepSeek最近发布的新模型DeepSeek-R1成为了人们热议的话题。这一改变游戏规则的模型于1月20日正式发布,并且其模型权重也随之开源,立刻在整个AI科技圈引发了强烈反响。据CNBC报道,这一新模型的推出引发了硅谷的恐慌,原因在于DeepSeek-R1不仅性能上超越了多款美国顶尖同类模型,同时在成本和算力消耗上也显示出了显著的优势。
引发业界关注的还有,知名半导体厂商超微半导体(AMD)宣布将DeepSeek-V3模型集成到其Instinct MI300X GPU芯片产品中。此举标志着DeepSeek与AMD的合作关系,将可能重塑AI推理领域的竞争格局。这种跨境的技术整合不仅可能对“英伟达+OpenAI”的现有市场主导地位造成冲击,也使得业内开始重新审视AI行业的未来走向。
DeepSeek-R1的成功并不是偶然。其开发团队在后训练阶段大量应用了强化学习技术,使得在极其有限的标注数据情况下,仍能取得出色的推理能力。在数学、程序代码及自然语言处理任务上,DeepSeek-R1的表现甚至和OpenAI的o1正式版相媲美。英伟达的资深研究科学家Jim Fan在个人社交上表示:“DeepSeek的这一成就让我们看到了一个新时代的来临,一个非美国公司的崛起,正在继续OpenAI最初所追求的使命:通过开放的前沿研究来惠及全人类。”
在国际市场上,DeepSeek的成功引起了众多科技领军人物的关注与探讨。比如,ScaleAI创始人Alexandr Wang在达沃斯论坛上直言,DeepSeek的新模型在推理效率方面表现十分卓越,值得业界对此严重看待。甚至有知名AI公司首席执行官直接称DeepSeek为“真正的OpenAI”,显现出对其能力的高度认同。
在硅谷巨头为DeepSeek的崛起所惊愕的同时,内部也有许多组织感到压力。来自Meta的内部信息显示,该公司的一些生成式人工智能团队员工正在“紧张”地分析DeepSeek的技术,试图从中寻找灵感以避免在市场中的竞争落后。Meta管理层也必须面对如何处理高昂的研发成本与DeepSeek在性价比上的强有力表现之间的矛盾,这为公司未来的财务规划带来了不小的压力。
DeepSeek的成功不仅在于其模型的技术突破,也在于其显著降低的训练成本。DeepSeek-V3的训练费用约为550万美元,相较于其他大型模型6000万美元以上的训练成本,显示出其在资源配置上的高效性。这种趋势正在改变人们对AI行业的认知,尤其是在美国,关于如何平衡研发费用和技术成就的讨论变得愈发迫切。在这样的背景下,市场上对于AI算力的需求也可能会面临重新洗牌的局面。
业内观察人士对这一现象有不同看法。有人认为DeepSeek提供的新技术可以使得AI大模型的开发变得更加普惠,同时降低对高端GPU的依赖。这也意味着更多的初创公司可能会进入这个市场,从而打破当前由几大科技巨头主导的局面。也有分析师指出,虽然DeepSeek的训练成本降低了,但这并不代表整体算力需求必然下降,因为数据处理的其他方面依旧需要大量的计算力支持。
DeepSeek-R1的崛起在全球范围内掀起了一场关于AI技术未来发展方向的深入讨论。随着技术的不断进步与创新,AI行业的生态格局必然会受益于这种激烈的竞争。而DeepSeek作为香港一颗冉冉升起的新星,正在为世界带来不同以往的机遇与挑战。无论是对参与者还是消费者未来的AI领域将更加充满可能。
