谷歌DeepMind与LIT AI实验室合作,强化学习微调提升语言模型决策能力
时间:2025-07-07 05:05
小编:小世评选
在当今快速发展的人工智能领域,语言模型的决策能力正在逐步获得关注。近日,谷歌DeepMind团队与约翰·开普勒林茨大学的LIT AI实验室达成合作,旨在通过强化学习微调技术,进一步增强语言模型在实际应用中的决策能力。这一创新合作为AI的未来发展提供了新的方向和思路。
背景与现状
随着大规模互联网数据的普及,数据训练出的语言模型已经展现出其超越文本处理的潜力,能够在复杂的交互环境中进行推理和决策。研究表明,语言模型能够通过自我生成的知识链推导出行动策略,但在实际执行过程中却出现了显著的不足。这种现象被称为“知道-行动差距”(knowing-doing gap),即模型能够识别出正确的策略,却无法有效地将其实施。
模型在决策时往往表现出过度偏向短期回报的倾向,称为“贪婪选择”(greediness)。而较为简单的模型在面对多样化的选择时,可能会因为频繁重复常见动作而产生“频次偏见”(frequency bias),从而降低整体决策的有效性。这些问题严重制约了语言模型在动态环境中的实用性。
DeepMind的创新解决方案
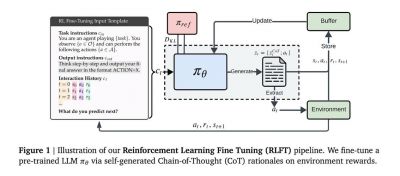
在这一背景下,谷歌DeepMind团队提出了一种创新的强化学习微调技术,以解决模型在推理与行动之间的脱节问题。该技术借助模型自生成的思维链作为训练信号,并对每一个推理过程的行动奖励进行系统性评估,促使模型优先选择逻辑自洽且高效的行动方案。
具体而言,模型会根据输入的指令以及过往的行动-奖励历史生成一个包含推理过程与动作的序列。通过运用蒙特卡洛基线评估和广义优势估计等优化技术,DeepMind能够在决策过程中有效地调整模型的行为。无效行动将会触发惩罚机制,而奖励塑造技术则能够确保输出格式的规范性,同时保持探索空间的足够广阔。
实验结果与成效
在进行的多臂老虎机(multi-armed bandit)测试中,该强化学习微调显著提升了模型的动作覆盖率。在10臂的测试中,模型的动作覆盖率提升了12个百分点,而面对20臂时虽然改善幅度较小,但频次偏见率却从70%骤降至35%。这一结果表明,强化学习微调有效地减少了模型在决策过程中对常见选项的过度依赖。
更为显著的是,在井字棋实验中,经过微调的模型在与随机对手的对战中胜率提升了5倍。同时,与最优蒙特卡洛树搜索代理的对战中,模型的平均回报从-0.95得以改善至归零,展现出出色的表现。值得注意的是,27B参数的大型模型在生成正确推理的概率已高达87%,而在未微调的情况下,仅有21%的概率能够执行最优动作。强化学习微调的引入有效缩小了这一差距,提升了模型的整体决策能力。
展望未来
谷歌DeepMind与LIT AI实验室的合作标志着人工智能领域的又一重要进展。通过强化学习微调技术的应用,语言模型在现实世界中的决策能力得以显著改善,展现出广泛的应用潜力。未来,随着技术的不断演进,AI能够在更多复杂的交互环境中发挥作用,为各行各业带来切实的效益。
这一研究成果为未来AI的开发和应用提供了重要的启示:如何有效结合语言处理与决策能力,将是后续研究的关注重点。随着人工智能的持续发展与成熟,我们期待看到更多类似的创新出现,推动整个领域的进步和应用需求的满足。
