达摩院推出VideoLLaMA 3,多模态视频-语言模型达到新SOTA
时间:2025-02-20 07:40
小编:星品数码网
最近,达摩院推出了一款新型的多模态视频-语言模型——VideoLLaMA 3,这一模型在多个性能评估维度上达到了新的状态最优(SOTA)。作为一个大小仅7B的模型,VideoLLaMA 3在通用能力、时间推理和长句处理等多个方面表现卓越,超越了众多现有的基线模型,展现了人工智能技术的新高度。
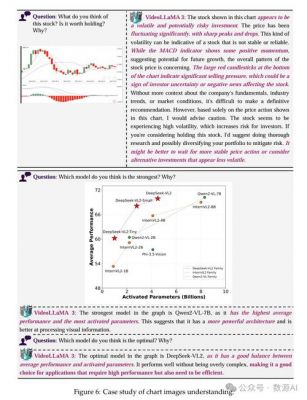
VideoLLaMA 3的设计理念中心围绕图片展开,这一思路在模型架构和训练过程中贯穿始终。该模型利用高质量的图像和文本数据进行构建,采用视频文本数据,显著提升了同参数量开源模型的能力。模型在多个基准测试中,如文档理解、图表解析、场景文本理解、数学推理以及常识问答等任务中,均展现出强大的表现。尤其是在InfoVQA的测试中,VideoLLaMA 3打破了以往纪录,而在MathVista的数学推理任务上更是展现了明显的优势,使得这一模型备受瞩目。
目前,VideoLLaMA 3已在Hugging Face上线,用户可以轻松体验其强大的功能。举例当用户上传《蒙娜丽莎的微笑》这幅名画并询问其在艺术界的历史影响和意义时,VideoLLaMA 3给出的回答详尽而准确,涵盖了艺术史背景以及这幅作品的深远影响。当用户向其询问关于一段视频的不寻常之处时,模型同样能够给出简练明了的分析,表现出其强大的语义理解能力。
VideoLLaMA 3得以实现这些优异性能的关键,正是建立在其创新的训练范式上。这一范式主要包括四个重要方面。视觉编码器能够处理动态分辨率的图像,通过多样场景的图像提升性能,使模型捕捉到更多的视觉细节。利用丰富的图像文本数据为多模态理解奠定基础,增强模型的空间推理能力,同时保留其语言能力。模型通过图像文本问答数据和视频字幕数据的微调,提升了遵循自然语言指令和进行多模态理解的能力。,强化模型在问答任务上的表现,使得其训练数据涵盖多样化的视频、图像和文本数据。
从框架设计来看,VideoLLaMA 3主要包含两个方面的创新。其一,采用了2D-RoPE替代了绝对位置嵌入,突破了传统固定分辨率的限制,使得视觉编码器可以处理各种分辨率的图像和视频,保证模型获取足够的细节信息。其二,针对视频数据冗余的问题,通过分析相邻帧之间的像素空间,并采用1-范数距离的方式修剪多余的数据,提高了视频处理的效率,减少了计算要求。
除了以上的框架设计,高质量数据对VideoLLaMA 3的高性能同样起到了至关重要的作用。研究团队构建了一个涵盖700万图像-字幕对的数据集VL3Syn7M,确保输入数据的质量。例如,在数据准备过程中,过滤了长宽比极端的图像,以保证模型特征提取的准确性。同时,利用美学评分模型筛选出了视觉效果佳的图像,保证模型学习到的内容精确且高质量。在此基础上,团队采用CLIP模型计算文本和图像的相似度进一步提升数据的有效性,进而保证模型对图文对的学习具有更高的代表性。
在训练不同阶段中,数据混合的策略同样保证了模型的丰富多样性。包括了来自多种数据集的图像数据,涵盖了一般场景、文档、图表、OCR(光学字符识别)等多类分类,以增强模型对视觉信息的认识能力。同时,通过指令跟随等微调阶段,使得模型在处理视觉和文本输入的任务中具有更强的指令遵循能力。
VideoLLaMA 3的核心训练和数据处理过程也得到了优化,通过对多个开源数据集中带注释的视频数据进行采集,结合流媒体和时间定位特征,进一步提升了模型的处理能力并有效减轻了灾难性遗忘的问题。
VideoLLaMA 3的推出不仅是达摩院在多模态AI领域的一次重大突破,更为视频和语言的交互型人工智能开辟了新的可能性。研究人员将这一模型的论文和相关demo都在Hugging Face和GitHub上做好了开放,期待更多用户的参与与反馈,助推多模态技术的进一步发展。对于这个充满潜力的模型,感兴趣的朋友可以通过以下链接进行深入体验:
论文地址:[https://arxiv.org/abs/2501.13106](https://arxiv.org/abs/2501.13106)
GitHub项目地址:[https://github/DAMO-NLP-SG/VideoLLaMA3/tree/main?tab=readme-ov-file](https://github/DAMO-NLP-SG/VideoLLaMA3/tree/main?tab=readme-ov-file)
Hugging Face demo(图像):[https://huggingface.co/spaces/lixin4ever/VideoLLaMA3-Image](https://huggingface.co/spaces/lixin4ever/VideoLLaMA3-Image)
Hugging Face demo(视频):[https://huggingface.co/spaces/lixin4ever/VideoLLaMA3](https://huggingface.co/spaces/lixin4ever/VideoLLaMA3)
在未来的科技发展中,VideoLLaMA 3定将成为推动AI智能化进程的重要助力。
